 |
Mastering Python Regular Expressions http://www.packtpub.com/ Authors : Félix López |
제3장 Grouping : ( )
그룹화는 다음과 같은 작업을 수행할 수 있는 강력한 도구입니다.
- quantifier를 적용하기 위한 subexpression생성
예) 단일 문자가 아닌 subexpression을 반복합니다. - alternation 범위를 제한
전체 표현식을 변경하는 대신 대체해야 할 항목을 정확히 정의할 수 있습니다. - 일치된 패턴에서 정보 추출
예) 주문 목록에서 날짜를 추출합니다. - 추출된 정보를 정규식에서 재사용(가장 유용한 기능)
예) 반복되는 단어를 감지하는 것입니다.
Introduction
subexpression 생성
괄호는 정규식 엔진에 괄호 안의 패턴이 하나의 단위처럼 취급되도록 한다.
import re
print(re.match(r"(\d-\w){2,3}", r"1-a2-b")) # <re.Match object; span=(0, 6), match='1-a2-b'>
capturing - Group은 매치된 pattern을 캡쳐한다, 이 후 여러operation(하위 method, 정규표현식)에 이를 이용
import re
expr = r"(\d+)-\w+"
data = "1-a\n20-baer\n34-afcr"
pattern = re.compile(expr)
match = pattern.finditer(data)
result = match.__next__() # 그룹 1로 이동
print(result.group()) # 일치 항목 전체 반환 = group(0) => 1-a
print(result.group(1)) # 그룹 1의 1번째 요소 반환 => 1
result = match.__next__() # 그룹 2로 이동
print(result.group(1)) # 20
result = match.__next__()
print(result.group(1)) # 34Backreferences(재참조)
정규표현식 및 sub함수에서 매칭된 그룹을 \index형식으로 재사용 가능
import re
expr = r"(\w+) \1" # \1 - 매칭된 첫째 그룹
data = r"hello hello world"
pattern = re.compile(expr)
match = pattern.search(data)
result = match.groups()
print(result) # ('hello',)
expr = r"(\d+)-(\w+)"
data = "1-a\n20-baer\n34-afcr"
replace = r"\2-\1"
pattern = re.compile(expr)
s = pattern.sub(replace,data)
print(s) # 'a-1\nbaer-20\nafcr-34'Named groups(이름지워진 그룹)
syntax : (?P<name>pattern)
Named groups 이용

import re
expr = r"(?P<first>\w+) (?P<second>\w+)"
data = r"Hello world"
pattern = re.compile(expr)
match = pattern.search(data)
print(match.group("first")) # Hello
print(match.group("second")) # world
#---------------------------------------
import re
expr = r"(?P<word>\w+) (?P=word)"
data = r"hello hello world"
pattern = re.compile(expr)
s = pattern.search(data)
print(s.groups()) # ('hello',)
#----------------------------------------
import re
expr = r"(?P<country>\d+)-(?P<id>\w+)"
data = "1-a\n20-baer\n34-afcr"
replace = r"\g<id>-\g<country>" # \g<name> - 이름에 의한 그룹
pattern = re.compile(expr)
s = pattern.sub(replace,data)
print(s) # a-1\nbaer-20\nafcr-34Non-capturing groups
무의미한 캡쳐된 그룹을 재사용, 참조되지 않게 설정
syntax : (?:pattern)
import re
expr = "Españ(?:a|ol)"
data = "Español"
match = re.search(expr,data )
print(match) # <re.Match object; span=(0, 7), match='Español'>
print(match.groups()) # () : Non-capturing groups / ('ol',) : capturing groups
Atomic groups : (?>pattern)
non-capturing group은 backtracking(되돌림, 재추적)를 비활성화하므로 패턴의 모든 가능성이나 경로를 시도하는 것이 의미가 없는 경우 회피할 수 있다.
※ regex 모듈 이용
import regex
expr = "(?>\w+)-\d"
data = "aaaaabbbbbaaaaccccccdddddaaa"
m = regex.match(expr,data)
print(m) # None[ "(\w+)-\d" 작업 순서 ]
1. regex engine은 처음 a와 매치한다.
2. regex engine은 대상의 모든 문자와 매치한다.
3. regex engine은 dash를 매치하지 못해 fail 상태이다.
4. regex engine은 backtracking하여 두번째 a를 가지고 1~3작업을 다시 수행한다.
5. 4작업 반복
[ automic groups 적용된 작업 순서 ] : 3번 작업에 의해 4~5가 의미 없어 회피
Special cases with groups
Python은 정규 표현식을 수정하거나 일치 항목에 이전 그룹이 있는 경우에만 패턴을 일치시키는 데 도움이 되는 몇 가지 형태의 그룹을 제공합니다.
Flags per group : (? letter)pattern

import re
a = re.findall(r"(?u)\w+", u"ñ")
print(a) # ['ñ']
b = re.findall(r"\w+", u"ñ", re.U)
print(b) # ['ñ']yes-pattern|no-pattern
이전 패턴이 발견된 경우 패턴을 일치시키려고 합니다. 반면에 이전 그룹을 찾지 못한 경우 패턴 일치를 시도하지 않습니다.
(?(id/name)yes-pattern|no-pattern)
이 id의 그룹이 매치하면 그 지점에서 yes-pattern이 매치, 그렇지 않으면 no-pattern 매치한다.
import re
expr = r"(\d\d-)?(\w{3,4})-(?(1)(\d\d)|[a-z]{3,4})$"
data = "34-erte-22"
data2 = "erte-abcd" # 그룹1 미일치하므로 그룹3무시
data3 = "34-erte" # 그룹1 일치하나 그룹3 yes-pattern 실시
pattern = re.compile(expr)
m = pattern.match(data)
print(m) # <re.Match object; span=(0, 10), match='34-erte-22'>
m2 = pattern.match(data2)
print(m2) # <re.Match object; span=(0, 9), match='erte-abcd'>
m3 = pattern.match(data3)
print(m3) # NoneOverlapping groups
import re
expr1 = r'(a|b)+'
expr2 = r'((?:a|b)+)'
expr3 = r'(a|b)'
data = 'abaca'
a1 = re.finditer(expr1,data)
for i in a1:
print(i)
'''
<re.Match object; span=(0, 3), match='aba'>
<re.Match object; span=(4, 5), match='a'>
'''
a = re.findall(expr1, data)
print(a) # ['a', 'a']
b = re.findall(expr2, data)
print(b) # ['aba', 'a']
c = re.findall(expr3, data)
print(c) # ['a', 'b', 'a', 'a']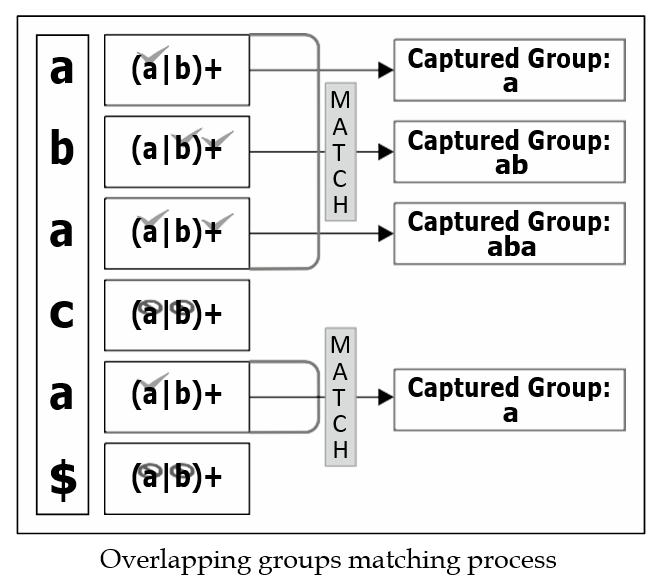
위의 그림에서 'abc'는 매치 상태이다. 그러나 캡쳐되는 그룹은 'a'이다(overlapping groups matching process)
이는 엔진이 모든 문자를 그룹화한다 하더라도 결과는 같다. 즉 마지막 'a'만 유지한다. 명심해야 할 것은 이것이 overlapping groups의 핵심이다.
'a', 'b'로 구성된 그룹을 capture하기 위하여 non-capturing groups를 이용하라!!!
'정규표현식' 카테고리의 다른 글
| [ Python ] 정규표현식 Table 및 우선순위 (0) | 2022.11.01 |
|---|---|
| [ python ] 정규표현식[5] (0) | 2022.10.31 |
| [ python ] 정규표현식[4] (0) | 2022.10.30 |
| [ python ] 정규표현식[2] (0) | 2022.10.27 |
| [ python ] 정규표현식[1] (0) | 2022.10.27 |



