 |
Mastering Python Regular Expressions http://www.packtpub.com/ Authors : Félix López |
제2장 Regular Expressions with Python
0. A brief introduction
1) 정규표현식 Test Site 추천
https://regex101.com/: 정규표현식 테스트 및 코드 생성 가능
https://regexr.com/ : 다른 언어에서 가장 대중적 Site
구글 colab : 온라인 코딩 Test site
2) 정규표현식를 이용한 검색 작업 순서
import re # 정규표현식 모듈 re ( 내장 모듈 ) import
expr = "[a-f]" # 정규표현식 작성
pattern = re.compile(expr) # 정규표현식 컴파일 -> 패턴객체 생성
data = 'hello' # Test를 원하는 문자열
result = pattern.findall(data) # 이하 - 패턴객체를 이용한 추가 작업
for i in result:
print(i) # eBackslash in string literals
정규표현식과 Test 문자열에 backslash(\)가 포함되면 Raw String 규칙 적용!!!!
r"문자열" 형식 - 문자열 앞에 r 추가
Building blocks for Python regex
PatternObject(RegexObject) : 정규식 컴파일한 결과물
re.compile('[a-f]')
MatchObject: 패턴객체의 search, match 메소드로 생성되는 매치된 패턴
<re.Match object; span=(1, 2), match='e'>
1. 컴파일(compile) : Pattern 객체 생성
pattern = re.compile(정규표현식, [옵션])
>>> import re
>>> expr = 'ab*'
>>> pattern = re.compile(expr)컴파일 옵션 : flag기능
정규식을 컴파일할 때 다음 옵션을 사용할 수 있다.
- DOTALL(S) - . 이 줄바꿈 문자를 포함하여 모든 문자와 매치할 수 있도록 한다.
※ re.DOTALL 옵션은 여러 줄로 이루어진 문자열에서 \n에 상관없이
검색할 때 많이 사용한다. - IGNORECASE(I) - 대소문자에 관계없이 매치할 수 있도록 한다.
- MULTILINE(M) - 각 줄마다 매치할 수 있도록 한다.
※ ^, $ 메타문자의 사용과 관계가 있는 옵션 - VERBOSE(X) - verbose 모드를 사용할 수 있도록 한다. ( 줄 단위로 주석처리 가능 #기호 사용 )
※ 문자열에 사용된 whitespace는 컴파일할 때 제거된다
단, [ ] 안에 사용한 whitespace는 제외
※ 옵션을 사용할 때는 re.DOTALL처럼 전체 옵션 이름을 써도 되고 re.S처럼 약어를 써도 된다.
◈ 사용 예[아래] : 4. compile flag
2. Searching(탐색)
Pattern객체의 Method

string 인수 : 탐색 대상
pos 인수 : 검색 시작 index
endpos 인수 : 검색 마지막 index
※ pos, endpos는 string slice의 [pos,end]와 동일 기능
# match, search 메서드 관련
import re
expr = '[a-z]+'
pattern = re.compile(expr) # re.compile('[a-z]+')
# match객체 관련
match1 = pattern.match('123python123 doc')
print(match1) # None -> 알파벳이 처음부터 존재하지 않아 None
match2 = pattern.search('123python123 doc')
print(match2) # <re.Match object; span=(3, 9), match='python'> -> position 3에서 발생하여 match
match3 = pattern.search('life is too short')
print(match3) # <re.Match object; span=(0, 4), match='life'> -> 1회만 시도
# findall, finditer 메서드
expr = '[a-z]+'
pattern = re.compile(expr)
match5 = pattern.findall('life is too short')
print(match5) # ['life', 'is', 'too', 'short']
match6 = pattern.finditer('life is too short')
print(match6) # <callable_iterator object at 0x016D1BB0>
print(list(match6)) # [<re.Match object; span=(0, 4), match='life'>, <re.Match object; span=(5, 7), match='is'>, <re.Match object; span=(8, 11), match='too'>, <re.Match object; span=(12, 17), match='short'>]패턴생성과 패턴관련 함수 축약 가능
- re. 패턴Method(정규식, 검사대상 문자열)
>>> m = re.match('[a-z]+', "python")
match객체의 Method
| Method | [ 정규표현식 group화 경우 ] | |
| group() | 매치된 문자열을 반환 | group( ) = group(0) group(n) - n번째 그룹 반환 group(n,m) - n, m요소 tuple로 반환 groups() - 그룹 요소 전체 tuple로 반환 groupdict() - " dict로 반환 (naming된 경우) # 그룹 이름지정시 index대신 이름 사용 가능 |
| start() | 매치된 문자열의 시작 위치를 반환 | start([group]) |
| end() | 매치된 문자열의 끝 위치를 반환 | end([group]) |
| span() | 매치된 문자열의 (시작, 끝)에 해당하는 튜플 반환 | span([group]) |
import re
expr = '[a-z]+'
pattern = re.compile(expr) # re.compile('[a-z]+')
match2 = pattern.search('123python123 doc')
print(match2) # <re.Match object; span=(3, 9), match='python'>
print(match2.group()) # python
print(match2.start()) # 3
print(match2.end()) # 9
print(match2.span()) # (3, 9))[ 주의 1 ] findall에서 *, ? 일치 - empty character, ^, $와도 matching 시도
import re
expr = 'a*' # 'a?' - 동일 결과
pattern = re.compile(expr)
a=pattern.findall("aba")
print(a) # ['a', '', 'a', '']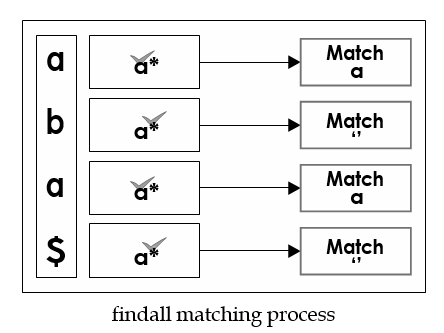
[ 주의 2 ] 그룹화 가능
# match객체 Method (그룹화)
import re
expr = r"(\w+) (\w+)"
data = "Hello world"
pattern = re.compile(expr)
mobj = pattern.match(data)
print(mobj.group()) # Hello world
print(mobj.group(0)) # Hello world
print(mobj.group(1)) # Hello
print(mobj.group(2)) # world
#print(mobj.group(3)) # IndexError: no such group
print(mobj.group(0,2)) # ('Hello world', 'world')
print(mobj.groups()) # ('Hello', 'world')
print(mobj.groupdict()) # {}
# findall 과 group
import re
expr = r"(\w+) (\w+)"
data = "Hello world hola mundo"
pattern = re.compile(expr)
result = pattern.findall(data)
print(result) # [('Hello', 'world'), ('hola', 'mundo')]
# finditer 과 group
import re
expr = r"(\w+) (\w+)"
data = "Hello world hola mundo"
pattern = re.compile(expr)
result = pattern.finditer(data)
match = result.__next__()
print(match.groups())
print(match.span())
# groups([default]) - 일치하는 그룹이 미존재시 표시할 기본값 지정
import re
pattern = re.compile("(\w+) (\w+)?")
match = pattern.search("Hello ")
print(match.groups()) # ('Hello', None)
print(match.groups("mundo")) # ('Hello', 'mundo')
# 이름 지정 : (?P<이름>pattern)
import re
pattern = re.compile(r"(?P<first>\w+) (?P<second>\w+)")
dic = pattern.search("Hello world").groupdict()
print(dic) # {'first': 'Hello', 'second': 'world'}
3. Modifying a string ( pattern객체의 Method )
split : 정규표현식 기준으로 string 분할

※ split method는 기본적으로 captured group를 list로 반환한다.
sub : string의 replace기능

불일치 시 대상 string 반환
repl 인수 : 대체 string - 함수가 될 수도 있다. 이 함수는 MatchObject를 인수로 받고 문자열을 반환
count 인수 : 반복 횟수
# split 기능
import re
expr = r"\W"
data = "Beautiful is better than ugly."
pattern = re.compile(expr)
result = pattern.split(data)
print(result) # ['Beautiful', 'is', 'better', 'than', 'ugly', '']
# maxsplit 적용
result = pattern.split(data,2)
print(result) # ['Beautiful', 'is', 'better than ugly.']
# group, maxsplit 적용
expr2 = r"(\W)"
pattern = re.compile(expr2)
result = pattern.split(data,2)
print(result) # ['Beautiful', ' ', 'is', ' ', 'better than ugly.']
# sub 기능
import re
expr = r"[0-9]+"
data = "order0 order1 order13"
replace = '-'
pattern = re.compile(expr)
result = pattern.sub(replace,data)
print(result) # order- order- order-
# 함수를 이용한 sub 기능
#함수는 match객체를 인수로 받아 string을 반환하는 형태여야 한다.
def normalize_orders(matchobj):
if matchobj.group(1) == '-': return "A"
else: return "B"
import re
expr = '([-|A-Z])'
data = '-1234 A193 B123'
replace = normalize_orders
pattern = re.compile(expr)
result = pattern.sub(replace, data)
print(result) # A1234 B193 B123
# group과 sub
import re
expr = r'\*(.*?)\*'
data = "imagine a new *world*, a magic *world*"
replace = r"<b>\g<1><\\b>"
pattern = re.compile(expr)
result = pattern.sub(replace, data)
print(result) # imagine a new <b>world<\b>, a magic <b>world<\b>
#sub와 subn 비교
import re
expr = r'\*(.*?)\*'
data = "imagine a new *world*, a magic *hello*"
replace = r"<b>\g<1>1<\\b>"
pattern = re.compile(expr)
result = pattern.sub(replace, data)
print(result) # imagine a new <b>world<\b>, a magic <b>world<\b>
result = pattern.subn(replace, data)
print(result) # ('imagine a new <b>world1<\\b>, a magic <b>hello1<\\b>', 2)4. compile flag
# DOTALL, S
import re
expr = 'a.b'
pattern1 = re.compile(expr)
pattern2 = re.compile(expr,re.DOTALL)
match1 = pattern1.match('a\nb')
match2 = pattern2.match('a\nb')
print(match1) # None
print(match2) # <re.Match object; span=(0, 3), match='a\nb'>
# IGNORECASE, I
expr= '[a-z]+'
pattern1 = re.compile(expr)
pattern2 = re.compile(expr,re.I)
match1 = pattern1.match('python')
match2 = pattern2.match('PYTHON')
print(match1) # <re.Match object; span=(0, 6), match='python'>
print(match2) # <re.Match object; span=(0, 6), match='PYTHON'>
# MULTILINE, M
expr= '^python\s\w+'
pattern1 = re.compile(expr)
pattern2 = re.compile(expr,re.M)
data = """python one
life is too short
python two
you need python
python three"""
match1 = pattern1.findall(data)
match2 = pattern2.findall(data)
print(match1) # ['python one']
print(match2) # ['python one', 'python two', 'python three']
# VERBOSE, X
expr= r"""
&[#] # Start of a numeric entity reference
(
0[0-7]+ # Octal form
| [0-9]+ # Decimal form
| x[0-9a-fA-F]+ # Hexadecimal form
)
; # Trailing semicolon
"""5. metacharacter 활용 예
import re
expr = 'Crow|Servo'
pattern = re.compile(expr)
match1 = pattern.match('CrowHello')
print(match1) # <re.Match object; span=(0, 4), match='Crow'>
# ^, \A 와 $, \Z
expr = '^python'
pattern = re.compile(expr)
data = """life is too short
python two
you need python
python three"""
match1 = pattern.match(data)
match2 = pattern.search(data)
print(match1) # None
print(match2) # None
pattern1 = re.compile(expr,re.M)
match3 = pattern1.search(data)
print(match3) # <re.Match object; span=(18, 24), match='python'>
expr = 'python$'
pattern = re.compile(expr)
data = """life is too short
python two
you need python
python three"""
match2 = pattern.search(data)
print(match2) # None
pattern1 = re.compile(expr,re.M)
match3 = pattern1.search(data)
print(match3) # <re.Match object; span=(38, 44), match='python'>
# \b 와 \B
expr = r'\bclass\b'
pattern = re.compile(expr)
data1 = "no class at all"
data2 = 'the declassified algorithm'
match1 = pattern.search(data1)
match2 = pattern.search(data2)
print(match1) # <re.Match object; span=(3, 8), match='class'>
print(match2) # None
expr = r'\Bclass\B'
pattern = re.compile(expr)
data1 = "no class at all"
data2 = 'the declassified algorithm'
match1 = pattern.search(data1)
match2 = pattern.search(data2)
print(match1) # None
print(match2) # <re.Match object; span=(6, 11), match='class'>
'정규표현식' 카테고리의 다른 글
| [ Python ] 정규표현식 Table 및 우선순위 (0) | 2022.11.01 |
|---|---|
| [ python ] 정규표현식[5] (0) | 2022.10.31 |
| [ python ] 정규표현식[4] (0) | 2022.10.30 |
| [ Python ] 정규표현식[3] (0) | 2022.10.27 |
| [ python ] 정규표현식[1] (0) | 2022.10.27 |



